
Ekonometria Wykład 7
Temat: Klasyczna Metoda Najmniejszych Kwadratów – założenia
Wykład ten poświęcony będzie Klasycznej Metodzie Najmniejszych Kwadratów. Możesz oczywiście też się spotkać z nazwą Klasyczny Model Regresji Liniowej, w skrócie KMRL. Obie nazwy są poprane i obie możesz śmiało wykorzystywać.
Przedstawię Ci oraz pokrótce omówię wszystkie podstawowe założenia tej metody. Dotyczą one głównie pewnych własności składnika losowego.
Warto znać te założenia, gdyż bardzo często zagadnienie to pojawia się na egzaminie z ekonometrii, ale nie tylko. Pamiętam dobrze, że wymienienie założeń KMNK trafiło mi się jako jedno z pytań na obronie pracy licencjackiej 🙂
Zatem zapraszam do lektury!
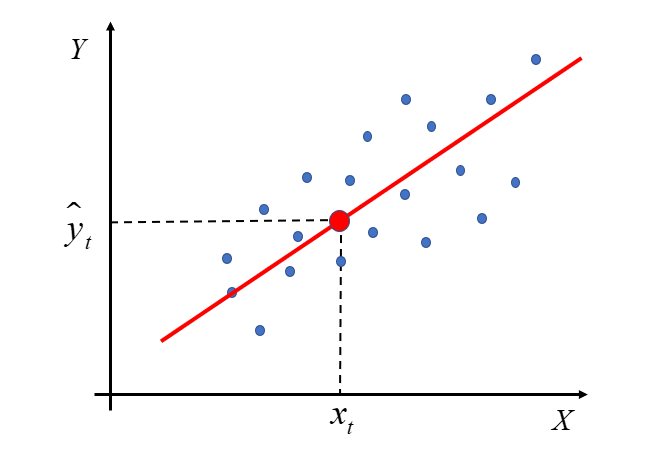
Zacznę od początku, czyli od samej nazwy. W poprzednim wykładzie omówiona została Metoda Najmniejszych Kwadratów. Jej istotę najbardziej odzwierciedla przykład modelu z dwiema zmiennymi – objaśnianą Y i jedną objaśniającą X. Klasyczna metoda najmniejszych kwadratów to po prostu określenie na wszystkie warunki stosowalności MNK do szacowania wektora 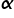 w modelu
w modelu
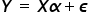
Tutaj zajmę się rozpisaniem na części pierwsze założeń Klasycznej Metody Najmniejszych Kwadratów. Są one bardzo istotne, ponieważ dopiero gdy te założenia są spełnione, czyli zebrane dane rzeczywiste do modelu ekonometrycznego posiadają wymiennie poniżej własności, to dopiero wtedy można zbudować model i zastosować metodę najmniejszych kwadratów do estymacji parametrów modelu.
Istnieją oczywiście inne metody estymacji parametrów modelu, mające swoje z góry ustalone „wytyczne”, np. uogólniona metoda najmniejszych kwadratów (UMNK), metoda największej wiarygodności (MNW), metoda regresji dwumianowej, itd.
Założenia KMNK są następujące:
- Szacowany model ekonometryczny jest liniowy względem parametrów
 .
. - Zmienne objaśniające są wielkościami nielosowymi o ustalonych elementach.
- Rząd macierzy równy jest liczbie szacowanych parametrów, czyli .
- Liczebność próby jest większa niż liczba szacowanych parametrów, tzn. .
- Nie występuje zjawisko współliniowości pomiędzy zmiennymi objaśniającymi.
- Wartość oczekiwana składnika losowego jest równa zero: .
- Składnik losowy ma stałą skończoną wariancję ;
- Nie występuje zjawisko autokorelacji składnika losowego, czyli zależności składnika losowego w różnych jednostkach czasu .
- Składnik losowy ma n-wymiarowy rozkład normalny: dla t=1,2,…,n.
Zauważ, że jest ich sporo.
Być może na swoich zajęciach miałeś ich mniej wypisanych. Na przykład, założenie 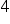 i
i 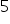 wynikają z założenia nr
wynikają z założenia nr 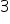 , więc mogły być pominięte. Często cztery ostatnie złożenia, dotyczące składnika losowego są ujmowane w jeden podpunkt.
, więc mogły być pominięte. Często cztery ostatnie złożenia, dotyczące składnika losowego są ujmowane w jeden podpunkt.
Postaram się teraz wyjaśnić bliżej znaczenie każdego z założeń.
Założenie 1. Szacowany model ekonometryczny jest liniowy względem parametrów 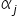 .
.
W jednym z poprzednich artykułów wyjaśniałam, kiedy model ekonometryczny jest liniowy względem parametrów, a kiedy liniowy względem zmiennych. Tutaj istotna jest liniowość względem nieznanych parametrów .
Ogólnie, w modelu typowo liniowym główną rolę odgrywa suma iloczynów typu 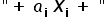 . To znaczy, że zarówno parametry, jak i zmienne powinny być jednocześnie w pierwszych potęgach, oraz zmienna objaśniana Y powinna być kombinacją liniową zmiennych objaśniających i różnych parametrów.
. To znaczy, że zarówno parametry, jak i zmienne powinny być jednocześnie w pierwszych potęgach, oraz zmienna objaśniana Y powinna być kombinacją liniową zmiennych objaśniających i różnych parametrów.
Stąd taki model można zapisać w postaci macierzowej: .
Wektor 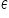 to wektor składników losowych (poszczególnych obserwacji) reprezentujących łączny wpływ wszystkich czynników drugorzędnych, przypadkowych, nie uwzględnionych wśród zmiennych objaśniających. Dodanie do składowej deterministycznej wektora zakłóceń losowych ma modelować fakt, że zarejestrowane obserwacje mogą różnić się co do wartości od wielkości wynikających z teoretycznej konstrukcji modelu ekonomicznego. Wektor grupuje składniki losowe które są z definicji nieobserwowalne, postulujemy ich istnienie, by wyjaśnić wszelkie rozbieżności między teoretycznymi wartościami zmiennej objaśnianej a wartościami zaobserwowanymi. W teorii jeśli wiemy ile jest istotnych zmiennych objaśniających (k) i jeśli wiemy, jaka jest postać zależności (liniowa), czyli jeśli Z1 jest prawdziwe, to epsilon obejmuje tylko czynniki przypadkowe, drugorzędne, zakłócające. W praktyce jednak trzeba liczyć się z tym, że składnik losowy obejmuje też konsekwencje następujących błędów:
to wektor składników losowych (poszczególnych obserwacji) reprezentujących łączny wpływ wszystkich czynników drugorzędnych, przypadkowych, nie uwzględnionych wśród zmiennych objaśniających. Dodanie do składowej deterministycznej wektora zakłóceń losowych ma modelować fakt, że zarejestrowane obserwacje mogą różnić się co do wartości od wielkości wynikających z teoretycznej konstrukcji modelu ekonomicznego. Wektor grupuje składniki losowe które są z definicji nieobserwowalne, postulujemy ich istnienie, by wyjaśnić wszelkie rozbieżności między teoretycznymi wartościami zmiennej objaśnianej a wartościami zaobserwowanymi. W teorii jeśli wiemy ile jest istotnych zmiennych objaśniających (k) i jeśli wiemy, jaka jest postać zależności (liniowa), czyli jeśli Z1 jest prawdziwe, to epsilon obejmuje tylko czynniki przypadkowe, drugorzędne, zakłócające. W praktyce jednak trzeba liczyć się z tym, że składnik losowy obejmuje też konsekwencje następujących błędów:
1. błędu specyfikacji (pominięcie istotnej zmiennej, włączenie nieistotnej itd.)
2. błędu aproksymacji (jeśli postać zależności jest inna czyli np. istotnie nieliniowa, i nie jest dobrze
przybliżana postacią liniową).
W praktyce liczymy się z tym, że Z1 nie jest idealnie spełnione (ale możemy zakładać, że dobrze dobraliśmy zmienne objaśniające i że prawdziwa postać zależności jest dobrze przybliżana przez zależność liniową…). Dokładniej własności zostaną opisane w punktach Z6-Z9.
Założenie 2. Zmienne objaśniające 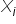 są wielkościami nielosowymi o ustalonych elementach.
są wielkościami nielosowymi o ustalonych elementach.
Zmienne objaśniające są nielosowe. Ich wartości traktowane są jako stałe w powtarzających się próbach.
Informacje zawarte w próbie są jedynymi, na podstawie których estymuje się parametry strukturalne modelu.
Uchylenie tego założenia powoduje utratę istotnych własności estymatorów.
Założenie 3. Rząd macierzy 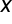 równy jest liczbie szacowanych parametrów, czyli
równy jest liczbie szacowanych parametrów, czyli 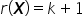 .
.
Rząd macierzy – jest to liczba liniowo niezależnych kolumn. Można też powiedzieć, że to liczba liniowo niezależnych wierszy. Jednakże w zapisie macierzowym wiersze – odzwierciedlają kolejne obserwacje, natomiast kolumny – kolejne zmienne objaśniające . Dlatego chodzi tu o niezależność pomiędzy zmiennymi objaśniającymi.
Założenia te zapewnia, że estymator można wyznaczyć w sposób jednoznaczny.
Z założenia 3 wynika od razu założenie 4 i założenie 5. Dlatego czasami wypisanie tych założeń osobno jet pomijane.
Założenie 4. Liczebność próby jest większa niż liczba szacowanych parametrów, tzn. 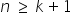 .
.
Liczba obserwacji n powinna być większa od liczby szacowanych parametrów (zmiennych objaśniających).
Założenie 5. Nie występuje zjawisko współliniowości pomiędzy zmiennymi objaśniającymi
Zmienne objaśniające nie mogą być współliniowe, tzn. wektory obserwacji zmiennych objaśniających (kolumny
macierzy X) powinny być liniowo niezależne.
Składnik losowy ma swoje konkretne własności, które powinny być spełnione w ramach założenia.
Kształtowanie się składnika losowego w modelu ekonometrycznym w ogólnej postaci jest jednym z podstawowych źródeł wiedzy na temat tego, czy model został zbudowany prawidłowo.
Jego wartość to różnica pomiędzy wartością empiryczną w danym okresie 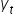 , a oszacowaną wartością teoretyczną dla wartości zmiennych objaśniających w danym okresie.
, a oszacowaną wartością teoretyczną dla wartości zmiennych objaśniających w danym okresie.
Z definicji model (w szerokim znaczeniu) to uproszczony obraz rzeczywistości. W takim razie budując model ekonometryczny, chcemy „uprościć” pewne zjawiska zachodzące w ekonomii, do postaci funkcji. Jednocześnie oczekujemy, że model będzie w jak najlepszym stopniu oddawał rzeczywistość, co za tym idzie różnica pomiędzy wartością, która wystąpiła w rzeczywistości (empiryczna), a tym co obliczyliśmy na podstawie modelu (teoretyczna), będzie jak najmniejsza, czyli jak najbliższa zeru.
Poniżej wymienione są własności składnika losowego. Choć brzmią one skomplikowanie, to jest to łatwiejsze niż się wydaje.
Zacznijmy od tego że, jeżeli składnik losowy kształtowałby się według jakiegoś schematu, to nie bardzo moglibyśmy mówić o jakiekolwiek losowości. Oznaczałoby to dla nas tyle, że w tej reszcie „coś się dzieje”, a model nie został zbudowany prawidłowo. Skoro widzimy, że coś się dzieje, to wypadałoby dojść do tego, co tam się kryje. Najprawdopodobniej w wartościach składnika losowego, w przypadku wystąpienia jego autokorelacji, zawarty jest jakiś czynnik mający spory wpływ na kształtowanie się zmiennej objaśnianej. Czynnik, którego nie wzięliśmy pod uwagę rozważając to, co może wpływać na badane przez nas zagadnienie. Jedną z szybkich metod, mających na celu oczekiwany spadek współczynnika autokorelacji jest dodanie do modelu zmiennej endogenicznej opóźnionej w czasie, ale o tym kiedy indziej bo to dużo bardziej skomplikowana sprawa.
Założenie 6. Wartość oczekiwana składnika losowego jest równa zero: 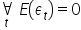 .
.
Wartości oczekiwane składników losowych są równe zeru ( dla t=1,2,…,n). Oznacza to, że zakłócenia reprezentowane przez składniki losowe mają tendencję do wzajemnej redukcji.
Założenie 7. Składnik losowy ma stałą skończoną wariancję 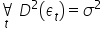 .
.
Wariancje składników losowych 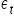 są stałe, tzn. dla t=1,2,…,n. Jest to tak zwana własność homoskedastyczności.
są stałe, tzn. dla t=1,2,…,n. Jest to tak zwana własność homoskedastyczności.
Macierz wariancji i kowariancji pomiędzy składnikami resztowymi jest postaci
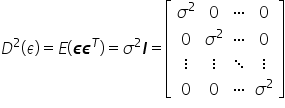
Założenie to zapewnia, że wartość wariancji zakłóceń nie zależy od numeru obserwacji.
Założenia 6 i 7 warunkują korzystne własności estymatora 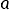 wektora parametrów , ale o tym w następnym wykładzie.
wektora parametrów , ale o tym w następnym wykładzie.
Założenie 8. Nie występuje zjawisko autokorelacji składnika losowego, czyli zależności składnika losowego w różnych jednostkach czasu 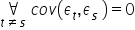 .
.
Składniki losowe i 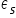 są od siebie niezależne. Nie występuje tzw. autokorelacja składników losowych.
są od siebie niezależne. Nie występuje tzw. autokorelacja składników losowych.
Oznacza to liniową zależność pomiędzy resztami modelu odległymi od siebie o „k” okresów. Dotyczy to modeli dynamicznych.
Jej występowanie oznacza, że pominięto w modelu jedną z istotnych zmiennych objaśniających lub przyjęto niewłaściwą postać modelu.
Założenie 9. Składnik losowy ma n-wymiarowy rozkład normalny: 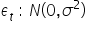 dla t=1,2,…,n.
dla t=1,2,…,n.
Każdy ze składników losowych ma ma rozkład normalny.
Założenie to dotyczące normalności rozkładu składnika losowego ma znaczenie przy wnioskowaniu statystycznym.
Jeżeli wszystkie powyższe cztery założenia w przypadku analizowanego przez nas modelu, okazują się być prawdziwe, to możemy składniki zakłócające pojmować jako generowane przez proces białego szumu. W takim przypadku wszystkie współczynniki autokorelacji oraz współczynniki autokorelacji cząstkowej będą zerowe, nieistotne statystycznie. By określić czy występuje biały szum, musimy dokonać testów odpowiednich hipotez. Wśród nich znajdują się np. statystyka Quenouille’a czy statystyka Durbina-Watsona.
W powyższym Wykładzie starałam się przybliżyć Ci założenia Klasycznej Metody Najmniejszych Kwadratów.
Wykład ten tak na prawdę powinien poprzedzać wykład o Metodzie Najmniejszych Kwadratów, gdyż najpierw powinny być postawione założenia, potem zastosowanie metody i wyprowadzanie wzorów na estymatory parametrów modelu.
Mam nadzieję, że jednak skoro już wiesz czym jest Metoda Najmniejszych Kwadratów oraz poznałeś założenia stosowalności tej metody, to regresja liniowa będzie Ci bliższa i nie taka straszna 🙂
KONIEC
Kliknij, aby powrócić na stronę z Wykładami do ekonometrii
