
Ekonometria Wykład 4
Temat: Dane do modelu
Wiesz już dokładnie czym jest model ekonometryczny. Kluczową rolę odgrywają w nim zmienne – objaśniana oraz objaśniające. Zanim jednak zaczniesz cokolwiek budować, musisz mieć odpowiedni materiał. Tym materiałem są dane statystyczne. Na ich podstawie wykonywać będziesz wszelkie potrzebne obliczenia.
Zebranie danych statystycznych jest istotnym krokiem w modelowaniu ekonometrycznym.
Zanim przedstawię Ci sposoby prezentacji zebranych danych, zacznijmy od początku, czyli od źródła. Oto kilka moich podpowiedzi, skąd możesz pobrać dane statystyczne:
- publikacje Głównego Urzędu Statystycznego GUS, np. Roczniki, Biuletyny Statystyczne, Wskaźniki, Sprawozdania, itp.;
- gotowe bazy danych statystycznych (dostępne na stronie GUS), np. Bank Danych Lokalnych BDL, Bank Danych Makroekonomicznych BDM, Dziedzinowe Bazy Wiedzy DBW, Portal Geostatyczny i wiele innych;
- publikacje Narodowego Banku Polskiego NBP;
- dane giełdowe;
- dane finansowe przedsiębiorstw;
- ankiety;
- inne…
Które ze źródeł wybierzesz, zależy przede wszystkim od typu zmiennej, którą chcesz wykorzystać w modelu.
W poniższym filmiku pokazałam, jak możesz łatwo, szybko i przyjemnie pobrać dane z największej bazy Głównego Urzędu Statystycznego, czyli z BDL:
Formy prezentacji danych
Gdy pobierzesz już dane statystyczne, trzeba je „ładnie” uporządkować. Mogą być one przedstawione w różnej formie. Oto trzy najczęstsze sposoby:
a) Dane szeregów czasowych – liczby, odpowiadające wartościom, jakie przyjmowała zmienna w kolejnych, jednakowo odległych momentach lub przedziałach czasu (np. latach, kwartałach, miesiącach).
Są to najbardziej popularne zbiory danych. Takimi danymi są np. PKB, zatrudnienie, stopa inflacji, liczba ludności, ilość aptek, liczba lekarzy, powierzchnia pól uprawnych, itp. Zestawiane są jako dane roczne, kwartalne, miesięczne a nawet dzienne (jak np. wartość jednostek uczestnictwa funduszy inwestycyjnych), czy godzinowe (kursy walutowe, stopy zwrotu papierów wartościowych).
W tabelce możesz je zestawić na przykład tak:
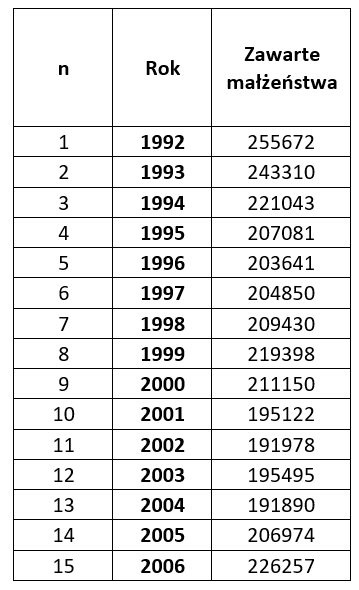
b) Dane przekrojowe – dane wyrażające stan zjawiska w ustalonym okresie czasu.
Dane przekrojowe powstają jako obserwacje dokonywane w tym samym czasie na wielu zmiennych.
Przykładem mogą tu być np. obserwacje budżetów gospodarstw domowych. Co jakiś czas przez Główny Urząd Statystyczny prowadzone są badania kilku tysięcy wybranych losowo gospodarstw domowych. Dzięki nim znane są informacje np. o dochodach i wydatkach badanych rodzin, o ich składzie demograficznym, o mieszkaniu i jego wyposażeniu w dobra trwałego użytku itd. Są to dane bardzo szczegółowe, obrazujące różnorodność badanych gospodarstw domowych.
Inny przykład powiązanych ze sobą zmiennych w przekroju roku:
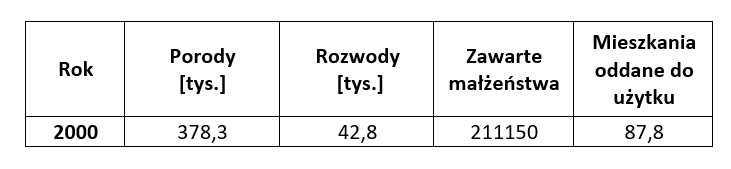
c) Dane panelowe (połączone, longitudinalne) łączą cechy danych szeregów czasowych i danych przekrojowych. Oznacza to, że masz kilka zmiennych określonych na przestrzeni kilku kolejnych okresów.
Przykład 1
Na podstawie danych szeregów czasowych możemy ustalić jak zmienia się z czasem odsetek pracujących kobiet. Na podstawie danych przekrojowych powinniśmy sprawdzić, jak odsetek ten zależy od wieku kobiet, ich poziomu wykształcenia, czy fazy cyklu rozwojowego rodziny. Ale dopiero dane panelowe umożliwiają ustalenie jak zmienia się na przykład struktura pracujących kobiet: kiedy kobiety rozpoczynają, przerywają i wznawiają prace.
Przykładowo, tak wygląda zbiór innych danych panelowych:
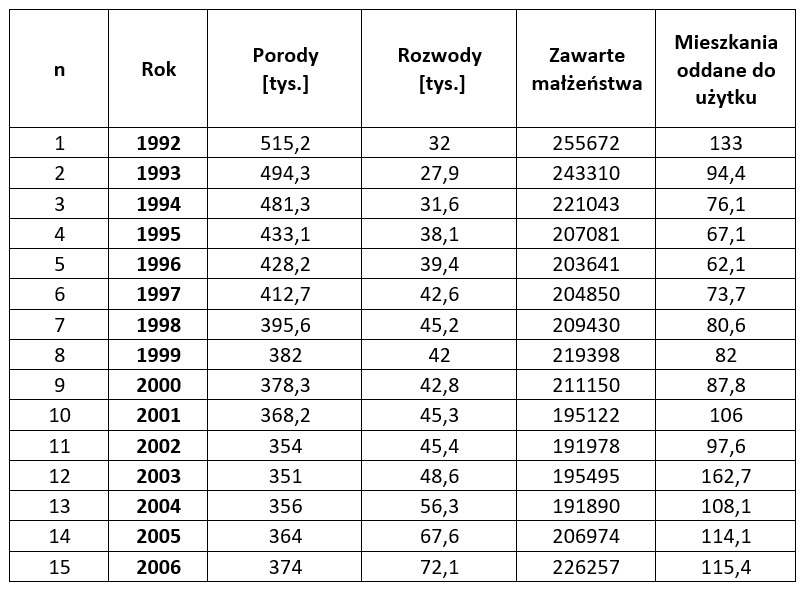
Oprócz danych zebranych ze znanych Ci źródeł statystycznych, wyrażonych liczbowo, możesz użyć do modelu zmiennych „nieliczbowych”. Przykłady: wykształcenie, płeć, stan cywilny, ocena samopoczucia, itp. O tym, jak to dokładnie zrobić, możesz poczytać w moim Artykule:
Zmienne zero-jedynkowe, czyli jak wyrazić słowa liczbami
Należy pamiętać, że nie wszystkie dane statystyczne, jakie uda Ci się znaleźć, będą odpowiednie i poprawne. Ich niedoskonałość, mająca swoje różnorodne przyczyny, może mieć niekiedy decydujące znaczenie dla oszacowanego modelu. Możemy dopatrywać się przyczyny złego działania modelu w jego równaniu, gdy w rzeczywistości błąd tkwi w zebranych danych statystycznych. Albo możemy męczyć się z szukaniem odpowiednich zmiennych do modelu, nie mając pojęciach o niedbale wypełnionych ankietach.
KONIEC
Kliknij, aby powtórzyć sobie, po co w modelu uwzględniany jest składnik losowy (poprzedni Wykład) <–
Kliknij, aby sprawdzić, jak zmierzyć siłę wzajemnego powiązania zmiennych (następny Wykład) ->
Kliknij, aby powrócić na stronę z Wykładami do ekonometrii

5 Komentarzy
W jaki sposób lub jakie dane najprościej wybrać np. 20 obserwacji i 3 zmienne, tak żeby dobrze się liczyło w Excelu ? Chodzi mi o model liniowy
Kamil
Jeśli zmienna objaśniana w modelu to indeks (np. indeks dynamiki produkcji przemysłowej w ujęciu kwartalnym rok do roku) to zmienne objaśniające powinny być analogicznymi indeksami?
Jola
Mam pytanie odnośnie układania, tworzenia zadań ekonometrycznych. Czy jest jakiś sposób na to, aby dane dobrać tak, żeby wyszedł mi model w postaci prostej, czyli np. Y=2X +1, Y=9x+4, itp?
Joanna Grochowska
Dobrać dane, w sensie samemu „ręcznie” coś wymyśleć, aby wychodziły takie proste modele? Czy chodzi o wybranie danych rzeczywistych (np z GUSu)?
Z rzeczywistymi danymi może być baaaaardzo ciężko.
Dane takie z głowy, ręczne to już prościej. Można zrobić taki myk, że najpierw ustalić sobie postać modelu, np. Y=2X+1 i potem wymyślać kolejne wartości zmiennej X, natomiast Y wyliczać z wzoru.
To jest dobra metoda, jeśli wybór takich danych jest potrzebny np. do celów edukacyjnych 🙂
Kamil
Mam pytanie odnośnie doboru zmiennych objaśniających do objaśnianej. Czy jeśli zmienną objaśnianą jest indeks dynamiki jakiegoś zjawiska (np. indeks produkcji przemysłowej w ujęciu kwartalnym rok do roku) to czy zmienne objaśniające powinny być również indeksami analogicznymi?